Distant reading is an umbrella term for methods of large-scale cultural analysis. These methods are often borrowed from the nomothetic sciences – ones that address general, theoretical questions. However, most often, digital humanists employ distant reading for answering idiographic questions – ones about unique cultural phenomena. In this talk I will argue that scholars of literature and other arts now have an opportunity to explore nomothetic questions – specifically, nomothetic questions about cultural change: a highly understudied research area. Dealing with such questions requires not only large databases and computational techniques, but also a theoretical framework – such as the theory of cultural evolution. I will present key components of the theory of cultural evolution and will discuss three of my studies that tackle the following general questions: 1) How do our shared cognitive preferences influence the evolution of art forms? 2) Does the order of entering a new genre influence the future success of an artist? 3) Does art become more complex over the course of its evolution?
Oleg Sobchuk is a postdoctoral researcher at the Max Planck Institute for the Science of Human History (Jena, Germany). He pursues general questions about the evolution of literature, films, and other arts, using large databases and computational methods. His work bridges digital humanities and the theory of cultural evolution.
https://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.png00Katja Mihurko-Ponizhttps://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.pngKatja Mihurko-Poniz2022-04-15 10:10:572022-04-15 10:14:01KEYNOTE LECTURE BY DR. OLEG SOBCHUK: DISTANT READING AND CULTURAL EVOLUTION: A METHOD MEETS A THEORY
In her talk prof. dr. Karina van Dalen-Oskam will take stock of where we currently stand in Computational Literary Studies and explicitly dream of what we may want to be able to do in the future. What could be the next steps towards more knowledge about the language and function of literature in Europe in the past and the present? What kind of data and tools would we need? Which other research disciplines come into view when we want to answer bigger and bigger questions? And what is the impact our research could have on the multilingual European academic and literary landscape?
Prof. dr. Karina van Dalen-Oskamis research group leader at Huygens Institute (Royal Netherlands Academy of Arts and Sciences) and professor of Computational Literary Studies at the University of Amsterdam. Her research focuses on computational literary studies and the development of methods and techniques for the stylistic analysis of modern Dutch and English novels. She applies these methods to analyze stylistic differences in texts, oeuvres, genres, time periods, and cultures or languages. Proper names in literary texts have her special interest. She is also interested in canon formation. She was project leader of The Riddle of Literary Quality (2012-2019) and currently leads, among other projects, Track Changes: Textual scholarship and the challenge of digital literary writing. At the University of Wolverhampton she is co-investigator in the project Novel Perceptions: Towards an inclusive canon in which the research done in the Dutch Riddle of Literary Quality project is being replicated in the United Kingdom.
https://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.png00Katja Mihurko-Ponizhttps://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.pngKatja Mihurko-Poniz2022-04-10 07:19:372022-04-10 07:21:55Keynote lecture by prof. dr. Karina van Dalen-Oskam: Distant Dreaming About European Literary History
Distant Reading Training School: Exploring ELTeC: Use-Cases for Information Extraction and Analysis within the COST Action 16204: Distant Reading for European Literary History
About the Training School
We invite you to the final Training School of the Distant Reading for European Literary History COST Action (CA16204), under the overarching topic of “Exploring ELTeC: Use-Cases for Information Extraction and Analysis”. This workshop consists of nine modules, including three lectures open to the online public, and takes a hybrid form, in which the participants can choose whether they prefer to participate in the training school in person or remotely. This is a single-track training school, therefore the participants are expected to participate in all, or at least most, sessions.
The Training School will present and teach hands-on approaches to information extraction and analysis of textual data, specifically ELTeC corpora developed within the Action. The workshops will cover various aspects of work with Named Entities and Geo-Entities, both in terms of their recognition and extraction, and their analysis, work with Wiki-ELteC data, linking (historical) data with Nodegoat, semantic analysis with word embeddings and language models, and comparing corpora with stylometry. While there are no formal entry knowledge requirements, given the topics and intensity of the workshop, we advise participation with at least very basic computer skills (ability to install programs, run simple scripts).
Key information • Date: 22-24 March 2022 • Place: Hybrid (online and in person) • Trainers: Christof Schöch (Trier University); Maciej Eder, Joanna Byszuk and Artjoms Šeļa (Institute of Polish Language, Polish Academy of Sciences); Diana Santos (University of Oslo); Benedikt Perak (University of Rijeka); Fotis Jannidis (Würzburg University); Denis Maurel, (Université de Tours, Lifat, Computer Science Research Laboratory); Eric Laporte, Tita Kyriacopoulou; (Université Gustave Eiffel, LIGM); Jessie Labov (Central European University); Cvetana Krstev, Ranka Stanković, Milica Ikonić Nešić (University of Belgrade),
• Host institution: Belgrade Serbia, University of Belgrade, Faculty of Mining and Geology • Organizers: Local organizers Ranka Stanković (ranka.stankovic@rgf.bg.ac.rs) and Cvetana Krstev (cvetana@matf.bg.ac.rs); Joanna Byszuk, Working Group 2 Leader (joanna.byszuk@ijp.pan.pl) • Contact persons: Roxana Patras (roxanapatras82@gmail.com), Training School Coordinator, Christof Schöch, Action Chair (schoech@uni-trier.de), Ranka Stanković (ranka.stankovic@rgf.bg.ac.rs), Joanna Byszuk, Working Group 2 Leader (joanna.byszuk@ijp.pan.pl), Diana Santos (d.s.m.santos@ilos.uio.no) • There is no fee for participation More on Distant Reading action • https://www.distant-reading.net/
Target Audience The target audience is formed of researchers, especially early-career investigators (ECI), from participating countries interested in Distant Reading, Digital Literary Studies, Corpus and Computational Linguistics and/or Literary Theory and their methodological uses across national traditions. Early Career Investigators (ECI) from Inclusiveness Target Countries (ITC) (http://www.cost.eu/about_cost/strategy/excellence-inclusiveness) are strongly encouraged to apply! The lecture parts of the Training School will be made broadly available in online form.
How to apply
We decided to offer call prolongation for online participants – if you want to participate in the TS remotely, you can apply until 11th March and will be notified by 15th of your acceptance. The application procedure is the same as in the original dates – you can find the information below.
To apply for participation in the TRAINING SCHOOL “Exploring ELTeC: Use-Cases for Information Extraction and Analysis”, please do the following things: Create an account on e-COST at https://e-services.cost.eu/user/registration/email Send the following documents as one PDF document (filename = your last name) to Roxana Patras (roxanapatras82@gmail.com) and Christof Schöch (schoech@uni-trier.de) until 25th February 2022:
a one-page Curriculum Vitae
a one-page motivation letter, including:
a clear statement of intent and your reasons to participate in a TITLE workshop;
information about your current level of knowledge / experience in using workshop-related digital tools;
what your expectations are (trainers & teaching materials);
a specification if you want to participate online or in person (with filling in the budget in the e-COST system).
After submission, all applicants are kindly asked to make sure they have received a confirmation of receipt within 24 hours. If this is not the case, please don’t hesitate to contact us again. Selection criteria Applicants will be notified of their acceptance until 4th March 2022. Basic COST eligibility criteria need to be met. Applicants with research interests relevant to the COST Action’s goals and activities are prioritized (Rank 1). Applicants who are early career researchers (including doctoral researchers) and applicants from COST Inclusiveness Target Countries (ITC) are prioritized over other applicants (Rank 2). Insofar as is allowable by the applications received and the selection criteria above, representation across as many COST countries as possible and a gender balance should be observed among the grantees (Rank 3). Where all the above criteria are satisfied, places are offered on a first-come-first-served basis (Rank 4)
RANGE OF TOPICS
Christof Schöch: introductory lecture about the project and about ELTeC (probably online). This lecture is an introduction to the objectives of the COST Action ‘Distant Reading for European Literary History’, with a particular focus on the structure of the core deliverable of the project, the multilingual European Literary Text Collection (ELTeC).
Maciej Eder, Joanna Byszuk, Artjoms Šeļa: Exploring and comparing ELTeC corpora with stylometry (online)
Diana Santos, NER exploitation and analysis (online)
Benedikt Perak: ELTeC Data Analysis, Representation of the Geo-Entities and Interlinking with Knowledge bases. (on site)
Fotis Jannidis, Leo Konle: Semantic analysis using word embeddings and language models. (online)
Ranka Stanković, Milica Ikonić Nešić: Wiki-ELTeC data session. Wikidata introduction; Wiki-ELTeC schema (all metadata from header plus main characters, their relations, places); pipeline for Wiki-ELTeC data population; predefined SPARQL query exploration. (on site) Hands-on: population of Wikidata for other languages.
Denis Maurel, Eric Laporte, Tita Kyriacopoulou, Cvetana Krstev: Unitex for processing of literary text: the case of NER automata. Enriching ELTEC texts by Named Entity Recognition using CasSys to parse texts with Unitex graph cascade of finite state transducers in different languages. (on site)
and 9. Jessie Labov: ELTec in Nodegoat 1) Introduction to the Nodegoat interface and how it works with this kind of data, 2) Using Nodegoat for working with the ELTeC data (specifically the NER), demonstrating how to enrich it by linking it to open data sources. (online)
DETAILED PROGRAM AVAILABLE SOON
Training schedule:
March 22, 2022
March 23, 2022
March 24, 2022
9-10
Christof Schöch: What is ELTeC all about? lecture
9-13
Diana Santos: NER exploitation and analysis 9-9:45 lecture 15 min break10:00-11:30 hands-on15 min break 11:45-13 lecture
9-13
Denis Maurel, Eric Laporte, Cvetana Krstev: Unitex for processing of literary text: the case of NER automata 9:00-10:30 lecture, 10:30-10.45 a small break 10:45-12h lecture 12:00-13:00 hands-on
10:15- 13:00
Maciej Eder, Joanna Byszuk, Artjoms Šeļa: Exploring and comparing ELTeC corpora with stylometry 10:15 – lecture intro 11:00 – Stylo intro hands-on 11:35-11:40 – a small break 11:40-13:00 – advanced hands-on
Jessie Labov, Pim van Bree, Geert Kessels: Linking historical data with Nodegoat: Introduction lecture
14:00- 16:00
Fotis Jannidis, Leonard Konle: Semantic analysis using word embeddings and language models. 14:00-15:15 lecture 15:15-16:00 hands-on
15:45 – 17:15
Benedikt Perak: ELTeC Data Analysis, Representation of the Geo-Entities and Interlinking with Knowledge bases 15:45-16:30 lecture 16:30-17:15 hands-on
16:15 -18:15
Pim van Bree, Geert Kessels: ELTec in Nodegoat hands-on
Biographical notes:
Trainers:
Christof Schöch (Trier University): Christof Schöch is Professor of Digital Humanities at the University of Trier, Germany, and Co-Director of the Trier Center for Digital Humanities. He is the chair of the COST Action Distant Reading for European Literary History. Find out more at https://christof-schoech.de/en.
Joanna Byszuk is a researcher at the Institute of Polish Language, Polish Academy of Sciences, as well as a member of the Computational Stylistics Group. Her research focuses on cross-lingual computational stylistics and advancing stylometric methodology and its understanding, especially locating method limitations and developing evaluation procedures. She is also interested in the concept of authorship and in discourse analysis in multimodal and collaboration perspectives. She is also the leader of Working Group 2: Methods and Tools within this COST Action.
Maciej Eder is the Director of the Institute of Polish Language at the Polish Academy of Sciences, and an Associate Professor at the Pedagogical University of Kraków, Poland (the latter part-time). His recent research is focused on computational stylistics, or stylometry. As a literary scholar, he is interested in Polish literature of the 16th and the 17th centuries: critical scholarly editions being his main area of expertise.
Artjoms Šeļa is currently doing postdoctoral research at the Department of Methodology of the Institute of Polish Language (Kraków) and is a research fellow at the University of Tartu (Estonia). He holds PhD in Russian Literature and uses computational methods to understand historical change in literature and culture. His main research interests include stylometry, verse studies and cultural evolution. Sometimes he makes forays into digital preservation and the history of quantitative methods in humanities.
Diana Santos has organized three NER evaluation campaigns for Portuguese, called HAREM, back in 2007-2009, and taught about NE in several venues, in Portugal and at ESSLLI. She is currently professor of Portuguese language, and Statistics for Humanities at the University of Oslo. Find out more at https://www.hf.uio.no/ilos/english/people/aca/dssantos/index.html
Benedikt Perak is an assistant professor at the Faculty of Humanities and Social Sciences, University of Rijeka, where he has been teaching courses in the fields of linguistics, digital humanities and data science. The research interest is related to the implementation and development of methods of digital humanities, NLP and data science. Find out more at https://portal.uniri.hr/Portfolio/1078
Fotis Jannidis (Würzburg University) is Professor for Digital Humanities at the University of Würzburg in Germany. His main field of research is the quantitative analysis of literary texts. Currently he is the coordinator of the priority program ‘Computational Literary Studies’ with 10 funded projects (Computational Literary Studies). Find out more at http://www.jannidis.de
Denis Maurel, (Université de Tours, Lifat – Computer Science Research Laboratory): Denis Maurel is Professor of computer science at the University of Tours, France. He contributes to the free software Unitex. He is actually working in a French ANR Project to use literature-based discovery in scientific biological papers. (https://www.univ-tours.fr/annuaire/m-denis-maurel
Eric Laporte is a Professor in Computer Science at Université Gustave Eiffel and a member of the LIGM laboratory. He is a linguist as well and his research is mainly about language resources for natural language processing. Find out more at http://igm.univ-mlv.fr/~laporte/index_en.html
Jessie Labov (Institute for Literary Studies, Humanities Research Center, Budapest) is a Researcher in the Literary Theory Department of the Institute of Literary Studies at the Eötvös Loránd Research Network, where she is developing a new project on Hungarian Literature as World Literature. She is also Vice-Chair of the NEP4DISSENT COST Action. Find out more at https://iti.abtk.hu/hu/munkatarsaink/adatlap/191-labovjessie.
Cvetana Krstev is a professor at the University of Belgrade, Faculty of Philology. Her research interests are building lexical resources for Serbian for NLP – corpora, electronic dictionaries, wordnet. She is the author of a tool for named entity recognition and annotation for Serbian SrpNER.. Find out more at http://poincare.matf.bg.ac.rs/~cvetana .
Ranka Stanković is an associate professor at the University of Belgrade, her field of research is NLP, semantic web, lexical resources, geoinformation management and deep learning. She is the Head of the Computer Center and the Chair for Applied Mathematics and Informatics, and Vice-president of the Language Resources and Technologies Society (JERTEH). Find out more at https://rgf.bg.ac.rs/eng/page.php?page=profesori_details&id=219
Milica Ikonić is a teaching assistant at the University of Belgrade, Faculty of Philology and PhD student of the Intelligent Systems programme at the University of Belgrade, her field of research is NLP, information extraction, linked open data and language models. Find out more at
https://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.png00Joanna Byszukhttps://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.pngJoanna Byszuk2022-02-17 15:28:322022-03-21 10:33:08Call for Belgrade Training School: “Exploring ELTeC: Use-Cases for Information Extraction and Analysis”
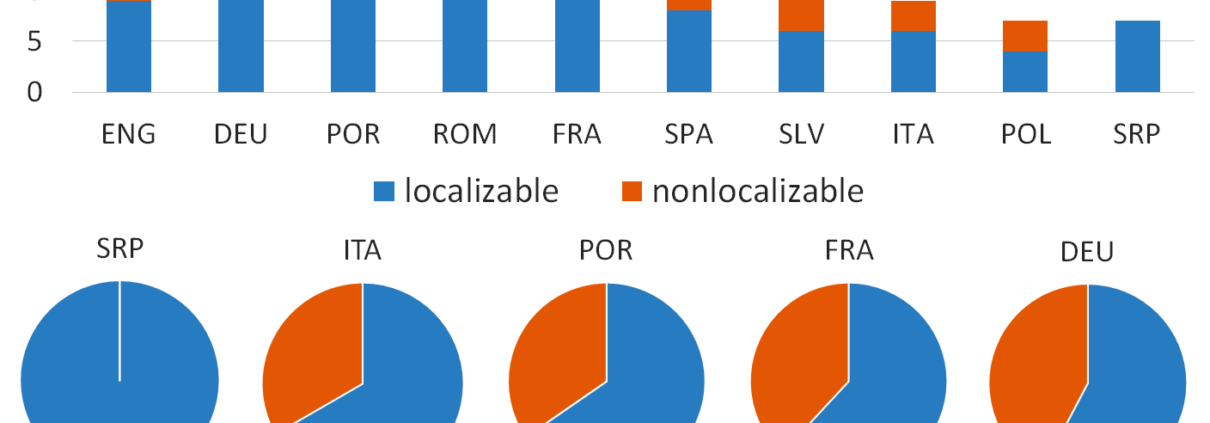
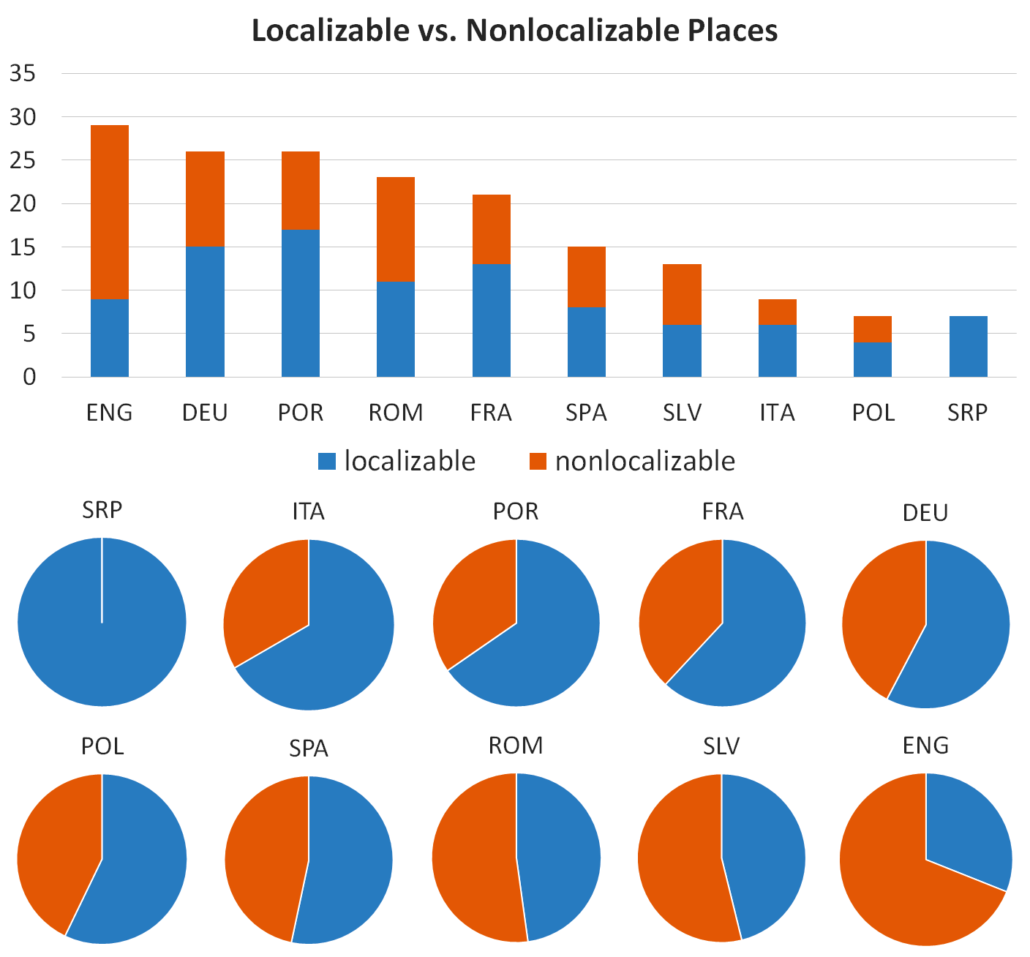
We celebrated the Day of Digital Humanities 2021 with the »Thresholds to the ‘Great Unread’: Titling Practices across Multilingual Collections of European Novels« webinar. As this year’s theme was multilingual DH, six Action members (Carolin Odebrecht, Rosario Arias, Berenike J. Herrmann, Cvetana Krstev, Katja Mihurko Poniž and Dmytro Yesypenko) presented the article Thresholds to the “Great Unread”: Titling Practices in Eleven ELTeC Collections« written by Roxana Patras, Ioanna Galleron and speakers of the webinar. The main aim of the paper, which will be published soon in the journal Interférences litteraires/literaire interferenties is to describe and, to a certain extent, to understand, titling practices in literary discourse through the exploration of a multilingual literary corpus comprising European novels published between 1840 and 1920. The study is based on the analysis of 11 out of the 16 sub-collections of novels, namely the English, French, German, Italian, Polish, Portuguese, Romanian, Serbian, Slovenian, Spanish, and Ukrainian sub-collections. The article focuses on an analysis of persons, places and genre entities in titles, and observe some regularities involving the “syntax” of these various entities in titles. If you missed the webinar, we invite you to watch the recording.
https://www.distant-reading.net/wp-content/uploads/Localizable_Nonlocalizable-Places-larger-2-1.png13081408Katja Mihurko-Ponizhttps://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.pngKatja Mihurko-Poniz2021-05-04 06:55:072021-05-04 07:19:47WEBINAR “THRESHOLDS TO THE ‘GREAT UNREAD’: TITLING PRACTICES ACROSS MULTILINGUAL COLLECTIONS OF EUROPEAN NOVELS”
This is a translation of an article about our recent Action meeting in Málaga, written by Cristina Fernández and originally published in Málaga Hoy on 18 February 2020. We are grateful for permission to publish this translation of the original article.
The project tries to search through distant reading for a common tradition in the 19th century novel
It would be absolutely impossible for a researcher to read all the novels written in 19th century Europe in an attempt to discover a common literary tradition in them. Not only would they have to live a thousand lives, but they would also have to know dozens of languages and be familiar with the many distant cultures. Now, computer methods can help in the study thanks to what Franco Moretti called distant reading.
Since November 2017, a four-year COST project financed by the European Union within its Horizon 2020 programme has brought together more than 200 people from some thirty countries in this task, providing a large and representative collection of texts in 12 languages to enable them to analyse common elements among themselves. From 17th to 19th February, more than fifty participants from 24 countries are meeting at the University of Malaga.
Literature to understand the world
Rosario Arias, professor of English Philology at UMA, is hosting the group that will share the different advances in the Link by UMA building on the Teatinos campus for three days. Christof Schöch, from the University of Trier in Germany, is the project’s Principal Investgator.
“Normally you read one novel, three or five to write a research paper but you can’t read thousands of texts because it takes time, and what we don’t want is for neglected texts to be forgotten,” Schöch explains. “You can use the computer and distant reading to get to more texts,” he adds.
Our Action members in Málaga
Almost a thousand digitized works written between 1840 and 1920
Project researchers are building a multilingual European literary text collection that already contains nearly a thousand digitized volumes published between 1840 and 1920 and a dozen languages. The aim is to reach 2,500.
“From each national tradition we are trying to select texts that are representative, from authors considered canonical and others less known, from men and women, short or longer novels,” explains Justin Tonra, a project participant from Ireland.
“This project tries to make a transnational comparison, but it is very difficult because each tradition is in itself different. That is why the project is very broad, it has many challenges, because we compare multilingual and multicultural traditions,” adds Tonra.
The Principal Investigator indicates that “we try to look for characteristics, features, that are easily comparable and that are common to different traditions such as names of places, of authors, of philosophers, of cities… it is a matter of tracing those elements”.
A collaborative and integrative work
Also, as Rosario Arias points out, “to find out if there is such a thing as what we suppose to be in the 19th century, which is a transition from the omniscient person to a more introspective narrative”. The description of professions, the importance of social class or religion, whether the novel takes place in rural or urban settings, whether this migration from the countryside to the city can be traced in different traditions and whether the same thing happens in the Slovenian, Greek, Italian or Spanish novel are questions to which they seek answers.
“The most relevant part of the project is not the tools, which are very interesting in themselves, nor the texts, above all it is to seek and propose the foundations of a European cultural identity with the collaboration of many individuals from different traditions, it is a very inclusive project, very integrating, the path is also part of the process, that is why we want to do it in a cooperative way, in a network”, says Schöch.
The answers are not easy, they are not black and white, they are difficult to reach because we are working with many researchers, many texts, many traditions, but the process itself is worth it. Until now, there has been no work at this level or in such a global and complete way on European literary history.
https://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.png00Justin Tonrahttps://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.pngJustin Tonra2020-03-09 11:02:032020-03-09 11:09:43UMA welcomes experts in European literature from 24 countries
Distant reading, driven by the development of digital technology in the human sciences, has emerged as one of the most prolific approaches to literary texts. Maps, graphs and trees, in Moretti’s (2005) words, allow us to reread famous works in a new way, or to look at large amounts of texts that have long been forgotten. However, often, approaches to distant reading disregard the acquisition of the data to be observed: Where do they come from? How are they created?
Our training school proposes to return to the crucial stage of data acquisition, focusing on details of the production chain of literary data. During the two-day course, we will start with OCR (optical character recognition), which makes it possible to transform an image into machine-readable text, addressing the difficulties introduced by the variation of graphic systems or the materiality of old artifacts. The second – decisive – step is the encoding in XML-TEI, which transforms the text into a usable database and allows to addition of more information to the text (e.g., author, gender, period) for ensuing analysis. The third and final step is the analysis with R, which allows hypotheses to be tested and patterns to be explored by analysing and visualising data.
Basel Public and University Library, venue for the Training School
With a strong emphasis on practical experience, this training school is geared towards building the framework for a first multilingual Swiss literary corpus (French, Italian and German). Tasks participating in its construction during the training school will provide an opportunity to discuss pertinent issues.
This course is part of a collective work carried out within the European COST “Distant Reading For European Literary History” project of which the organizers are the Swiss representatives: https://www.distant-reading.net/
The working language of the training school is English, knowledge of at least one of the three languages of the literary data (French, Italian, German) is also required.
All information, including the full training school programme, can be found in French, German, and Italian here and here.
Registration process: target group of the training school isdoctoral students affiliated with the universities of Basel, Bern, Fribourg, Geneva, Neuchâtel and Lausanne as well as from the EPFL. Post-doc researchers can apply via a short email pending registration of PhD students who have priority.
Please register by sending an email to alexandre.camus@unil.ch Participation is free of charge for doctoral students. All travel and accommodation expenses are covered by the doctoral program.
Practical information:
Course title “Distant Reading – Tools and Methods”
Instructors: Simon Gabay, Berenike Herrmann, Simone Rebora, Elias Kreyenbühl
Date: 12 and 13 December 2019
Location: Basel Public and University Library (UB)
https://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.png00Justin Tonrahttps://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.pngJustin Tonra2019-11-13 14:55:102019-11-13 14:55:11Invitation to Doctoral Training School: “Distant Reading – Tools and Methods.” Basel, 12-13 December 2019.
The First Workshop on Distant Reading in Portuguese will take place on 27-28 October 2019 at the University of Oslo, and will feature a presentation on our COST Action on Distant Reading for European Literary History by Isabel Araújo Branco, Diana Santos, Paulo Silva Pereira and Raquel Amaro.
Leitura distante em Português (Distant Reading in Portuguese) Image created by Oriel Wandrass, Universidade Estadual do Maranhão (UEMA)
At the conference, which features additional presentations by members of our Action, participants will illustrate the state of the art, discuss research questions for the medium and long term, and to take a position on several Portuguese-related matters within the sphere of Distant Reading.
Further details, including the programme of the workshop and abstracts, are available here: Portuguese | English (via Google Translate).
This guest post, written by Monika Barget, project manager at the Centre for Digital Humanities, Maynooth University, Ireland, reports on one of the two recent Distant Reading Training Schools that were held at the inaugural European Association for Digital Humanities Conference in Galway, Ireland.
Two of my colleagues from Maynooth University and I attended the COST Action Training Schools at the EADH 2018 conference in Galway. While one of us signed up for the theory sessions, discussing different approaches to ‘style’ in the digital humanities, an early career researcher in Early Irish and I (currently working as project manager in Digital Humanities) attended the sessions on methods and tools of ‘Distant Reading’. Our workshop group was very international and brought people from various disciplines together. Most of us had only recently started to extensively use digital tools for data/text analysis and had limited programming experience. That was why the step-by-step introductions to different technology-supported methods of topic modelling, stylometry, and data visualisation were a perfect fit. We were introduced to downloadable software with elaborate graphic user interfaces (e.g. TXM and Gephi) as well as portable software (Dariah Topics Explorer) in development and a stylometry tool based on R-libraries, which required working in the command line.
Participants at the Methods & Tools Training School, Galway (5-7 December 2018)
The corpora chosen by the workshop facilitators were mainly selections of British fiction, the North-American Brown Corpus and some smaller fiction corpora in other European languages (French, Italian, Hungarian, Slovene). For me as a historian specialising in visual cultures and politics of the early modern period, these were uncommon sources, but at the end of most workshop sessions, I had some time to apply each method and tool to my own corpora (e.g. a collection of political letters from Ireland). The workshop facilitators made sure that all participants were able to keep step and competently answered our questions. As not all methods and tools presented to us will, however, be equally relevant to our future research, additional ‘experimental time’ to work with just one of the methods/tools in smaller groups on the last workshop day would have been even more beneficial. There was a lot to take in, and a longer supervised ‘lab’ session focusing on a chosen method and my own material would also have aided me to process and practice what I had learned. In this way, the instructors, too, could have received more in-depth feedback, especially in those cases where their tools were still being updated and improved.
Nonetheless, the overall timing of the workshop suited me very well as we had the opportunity to connect with other participants during coffee breaks, lunch, and in the evenings. It was interesting to hear how other scholars at a similar career level were going to use topic modelling, stylometry, or network analysis in their projects, and I learned a lot about the institutional frameworks and digital cultures in other universities. Finally, the vivid keynote lecture delivered by Prof. Christof Schöch was a convenient occasion to sit back and reflect on some of the overarching challenges behind digital literary analysis. I am very grateful for the opportunity to attend the COST Action Training School and will recommend it to my peers.
https://www.distant-reading.net/wp-content/uploads/distant-reading_icon_v3a.png286301Justin Tonrahttps://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.pngJustin Tonra2018-12-13 12:29:302019-10-12 13:21:48Methods & Tools: a Report on the Distant Reading Training School
Following our recent Action meetings in Antwerp, WG2 member and Chief Content Architect at Wolters Kluwer Germany, Christian Dirschl, offered the following thoughts on our project from his perspective as an Information Scientist working in an industrial setting.
At the beginning of October, I participated in the meeting of Working Groups 2 and 3 in Antwerp. I am an Information Scientist who usually works on legal information and not literary texts, so I considered myself as an outsider to this group. Still, I joined WG2 and was very curious about how the digital humanities is dealing with the specific challenges it faces.
I felt very welcome! Both from the people at the meeting, but also from the discussions that were going on, which sounded quite familiar to me.
There were discussions about the balancing act of enriching documents by human experts versus automatically by machines. Another angle was about offering basic technological infrastructure or aiming at sophisticated and complex algorithms, which might not reach the maturity level that would be required in an operational environment. And then, there were open questions: whether to head for a single technology that serves all languages, or whether dedicated mono-lingual tools would be superior in the end—with the drawback that the results would hardly be comparable across the whole corpus.
Members of our Action bask in the Antwerp sunshine after three days of meetings last week.
My own experience with these technologies is very similar and obviously, there is no right or wrong answer. A complex challenge requires a complex solution—or a magic wand!
Although Deep Learning sometimes appears to be this wand, it was clear from the start that its application area in this Action is important, but limited. So, other solution streams also need to be investigated. I am looking very much forward to seeing what the final decision will be.
The Action has an interesting and ambitious goal and there were enough dedicated experts around the table to make sure that quite a lot will be achieved within the limited available resources.
What I have learned in the last five years or so is that technical progress needs to be aligned to customer needs, or rather, in this case, researchers’ requirements. And I have the impression that academia in general is still very much on an exploratory path. Most of the times, this will lead to more knowledge, but less applicability. So my advice is to spend quite some time on a regular basis on whether the intermediate results show progress on current (!) research requirements and not only in general and then to adapt to this feedback, so that an optimal practical solution is finally achieved. This may sound odd for some researchers, but in my experience this is the most efficient way to go forward.
I really enjoyed the two days in Antwerp and I am looking forward to further collaboration in the future. All the best to the Action and its participants!
https://www.distant-reading.net/wp-content/uploads/antwerp_group_pic.jpg30004000Justin Tonrahttps://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.pngJustin Tonra2018-10-17 08:50:172019-10-12 13:22:32Information Science and Distant Reading: an Industry Perspective
https://www.distant-reading.net/wp-content/uploads/distant-reading_icon_v3a.png286301Roxana Patrashttps://www.distant-reading.net/wp-content/uploads/distantreading_logo-high-300x138.pngRoxana Patras2018-10-11 14:27:262019-10-12 13:22:49Call for Applications – GALWAY TRAINING SCHOOL (5-7 December 2018)
We may request cookies to be set on your device. We use cookies to let us know when you visit our websites, how you interact with us, to enrich your user experience, and to customize your relationship with our website.
Click on the different category headings to find out more. You can also change some of your preferences. Note that blocking some types of cookies may impact your experience on our websites and the services we are able to offer.
Essential Website Cookies
These cookies are strictly necessary to provide you with services available through our website and to use some of its features.
Because these cookies are strictly necessary to deliver the website, refusing them will have impact how our site functions. You always can block or delete cookies by changing your browser settings and force blocking all cookies on this website. But this will always prompt you to accept/refuse cookies when revisiting our site.
We fully respect if you want to refuse cookies but to avoid asking you again and again kindly allow us to store a cookie for that. You are free to opt out any time or opt in for other cookies to get a better experience. If you refuse cookies we will remove all set cookies in our domain.
We provide you with a list of stored cookies on your computer in our domain so you can check what we stored. Due to security reasons we are not able to show or modify cookies from other domains. You can check these in your browser security settings.
Other external services
We also use different external services like Google Webfonts, Google Maps, and external Video providers. Since these providers may collect personal data like your IP address we allow you to block them here. Please be aware that this might heavily reduce the functionality and appearance of our site. Changes will take effect once you reload the page.
Google Webfont Settings:
Google Map Settings:
Google reCaptcha Settings:
Vimeo and Youtube video embeds:
Privacy Policy
You can read about our cookies and privacy settings in detail on our Privacy Policy Page.